
There are plenty of great ways to find information on the internet. Still, there is some information that's harder to find, especially if you're looking for very specific things. Web scraping services are a great tool for this. Scrapestack is an API that lets you manage your own web scraping.
A web scraper is a tool that will visit a website and take a copy of a specific type of data. Rather than you going through everything manually, just give the scraper data to look for and it will do all the work. Scrapestack is more powerful than the free website scrapers out there. It provides better security, better reliability, and a top of the line server.
Getting Started
Getting started with Scrapestack is very easy. First, you'll need to set up an account. Once you have an account, you will be given an API key. This is what you will use to access the API, unsurprisingly. You can then use the target URL to scrape data from any website you want.
http://api.scrapestack.com/scrape?access_key=YOUR_ACCESS_KEY&url=https://microsoft.com
In the example above you would be scraping Microsoft's website. All you need to do is place your API key in the appropriate spot and change the domain at the end. You will then be given the page's contents without JavaScrip and CSS styles.
There are other parameters you can add to that target URL to further refine things.
|
|
[Required] Specify your unique API access key to authenticate with the API. Your API access key can be found in your account dashboard. |
|
|
[Required] Specify the URL of the web page you would like to scrape. |
|
|
[optional] Set to |
|
|
[optional] Set |
|
|
[optional] Specify the 2-letter code of the country you would like to us as a proxy geolocation for your scraping API request. Supported countries differ by proxy type, please refer to the Proxy Locations section for details. |
|
|
[optional] Set |
Pricing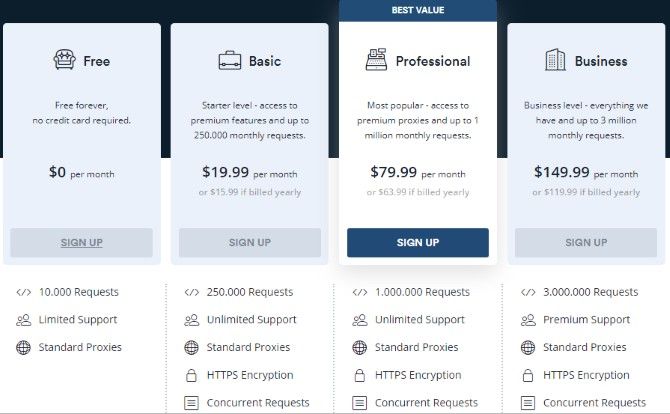
There are several pricing tiers for Scrapestack. The free tier offers 10,000 API requests, standard proxies, and limited support. The Basic tier adds 250,000 API requests, HTTPS Encryption, concurrent requests, and unlimited support. Basic costs $19.99 a month. Bumping up to the Professional tier gets you 1,000,000 requests, and then the Business tier goes all the way up to 3,000,000 requests. They cost $79.99 and $149.99 a month, respectively.